
A deep dive into Kubeflow pipelines

Andreea Munteanu
on 22 March 2024
Widely adopted by both developers and organisations, Kubeflow is an MLOps platform that runs on Kubernetes and automates machine learning (ML) workloads. It covers the entire ML lifecycle, enabling data scientists and machine learning engineers to develop and deploy ML models. Kubeflow is designed as a suite of leading open source projects that enable different capabilities such as model serving, training or hypertuning optimisations.
At Canonical, we deliver Charmed Kubeflow – an official distribution of the upstream solution with additional security maintenance, tool integrations, and enterprise support and managed services – so we know a thing or two about the project. In our experience, one of the most important concepts to understand with respect to both Kubeflow itself and the broader ML lifecycle is machine learning pipelines. Taking advantage of pipelines is the best way to effectively deploy models at scale in production, so let’s break down this critical component in the MLOps landscape.
Machine learning pipelines
A machine learning pipeline is an important component of ML systems, ensuring simplified experimentation and capability to take models to production. They are a series of steps that automate how ML models are created, in order to streamline the workflow, development and deployment. ML pipelines simplify the complexity of the end-to-end ML lifecycle, helping professionals to develop and deploy models. Amongst their benefits, ML pipelines ensure scalability thanks to their ability to handle large volumes of data while supporting collaboration and reproducibility.
A core value of MLOps platforms such as Kubeflow is that they enable professionals to build and maintain ML pipelines.
What is Kubeflow Pipelines?
Kubeflow Pipelines or KFP is the heart of Kubeflow. It is a Kubeflow component that enables the creation of ML pipelines. It is used to help you build and deploy container-based ML workflows that are portable and scalable. The main goals of Kubeflow Pipelines are to simplify the following processes:
- Orchestration of the end-to-end ML pipelines
- Experimentation with various ideas and techniques
- Experiment management
- Reuse of components and pipelines to enable users to quickly put together end-to-end solutions without having to re-build each time
Components of Kubeflow Pipelines
Components of Kubeflow Pipelines
Kubeflow Pipelines is part of the Kubeflow project. It can be used as part of the project or as an independent tool. It is made of 3 main components:
- User interface (UI) for managing and tracking experiments, jobs, and runs
- Engine for scheduling multi-step ML workflows
- SDK for defining and manipulating pipelines and components

Kubeflow Pipelines use cases
Kubeflow Pipelines are typically most useful for advanced users of Kubeflow or professionals who already have experience with machine learning. You don’t necessarily need KFP in the experimentation phase of the ML journey, but it becomes useful when you want to take your models to production. The main use cases for KFP include:
- Workflow automation: Data scientists and machine learning engineers often perform a lot of the initial experimentation phase manually to better understand optimisation possibilities and quickly iterate. But once they have defined their workflow, they can use KFP to automate the process and save time.
- Model deployment to production: Models are usually compiled in a binary file. Traditionally, for the model to be loaded to a server where the requirements for inference are met, this file would be manually copied to the machine that hosts the application. KFP simplifies this process by enabling you to build automated pipelines to multiple applications or servers.
- Model maintenance and updates: The ML lifecycle is an iterative process and models need to be updated periodically. KFP helps users run updates and rollbacks across multiple applications or servers. Once the model is updated in one place and the update transaction is complete, KFP ensures the update is quickly applied to all client applications.
Multi-tenant ML environment: Organisations often have large data and ML teams that need to share their resources. KFP enables simple and effective sharing of the environment, where each collaborator gets an isolated environment. It is then utilised by the K8s cluster and tools such as Volcano to schedule resources or manage containers. This helps professionals isolate workflows and monitor pending and running jobs for each person involved.
Benefits of KFP
Among machine learning specialists, Kubeflow Pipelines is widely adopted for a number of reasons. The most important benefits of KFP include:
- Streamlined workflow automation: Kubeflow Pipelines allows users to define the machine learning pipelines as a sequence of steps, each with its input, output, and dependencies. This leads to streamlining the machine learning workflows, and reduces the overhead and complexity of managing and executing your pipelines.
- Improved collaboration: Kubeflow Pipelines provides a central and shared platform for data scientists, machine learning engineers, and IT operations teams to collaborate on machine learning projects. It allows them to share pipelines and artifacts with others, and enables the tracking and monitoring of the pipelines across the entire organisation.
- Enhanced performance and scalability: Kubeflow Pipelines runs on Kubernetes, which provides a scalable and flexible infrastructure for running machine learning pipelines and models. This allows you to easily scale up and down the pipelines, and ensure that your pipelines are performant and reliable.
- Resource optimisation: KFP is a cloud native application, so it can leverage the resource schedulers that Kubernetes platforms provide. This leads to optimised usage of the existing resources and faster project delivery.
- Extensive support for popular machine learning frameworks: KFP provides built-in support for popular machine learning frameworks like TensorFlow, PyTorch, and XGBoost, as well as a rich ecosystem of integrations and plugins for other tools and services. Charmed Kubeflow goes a step further and enables additional integrations with tools and frameworks such as NVIDIA NGC Containers, Triton Inference Server and MLflow.
Whereas Kubeflow Pipelines is a feature-rich tool, it still raises some challenges for beginners. It comes with a steep learning curve and there is limited documentation available. Since it is a fully open source tool, there is a big community that can help beginners, but it can be frustrating at times. You can alleviate these challenges by taking advantage of enterprise support or managed services from organisations which distribute Kubeflow.
Architecture of Kubeflow Pipelines
Kubeflow Pipelines is a complex component with capabilities that unblock users and enable them to automate their workflows and reduce their time spent on manual tasks. As outlined in the kubeflow.org documentation, the following architecture depicts these capabilities. Please note that some of the tools such as MySQL for the ML Metadata or MinIO for artefact storage can be replaced, depending on the expertise that organisations have as well as what they already might use in-house.
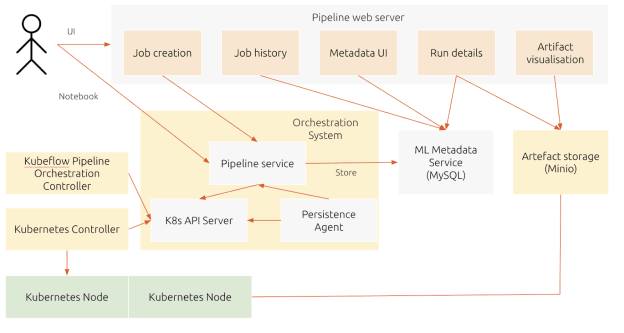
Diagram based on kubeflow.org’s architectural overview
As the diagram illustrates, users can interact with KFP either through the user interface or through development tools such as Notebooks. Initially, users create components or specify a pipeline using the Kubeflow Pipelines domain-specific language (DSL). Once defined, the compiler transforms the Python code into a YAML static configuration. Then, the Pipeline Service creates a pipeline run from the static configuration. It calls the server of Kubernetes API for creating the necessary Kubernetes resources (CRDs) to run the pipeline. If you have a resource scheduler integrated, you can use it to run the pipeline when resources are available or at a desired time. To complete the pipeline, the containers are executed within the Kubernetes pods, using orchestration controllers.
Two types of data can be stored. The first type is metadata, which includes experiments, jobs, pipeline runs, and single scalar metrics. The second type is artefacts, which includes pipeline packages, views, and large-scale metrics (time series). Metadata is stored in a MySQL database, whereas artefacts are stored within MinIO. Storing them in an external component also enables portability, so artefacts can be migrated to different clusters or environments.
Kubernetes resources created by the Pipeline Service are monitored by the Persistence Agent. To enable reproducibility, the input and output of the containers are recorded. It enables professionals to use the configurations and replicates different tasks, also being able to check if the results match. They consist of parameters or data artefact URIs and are seen as metadata.
The Pipeline web server enables users to get a visual understanding of the steps from the Kubeflow Pipelines. It presents various information, including a list of pipelines currently running, history of pipeline execution, data artefacts and logs for debugging.
Get started with Kubeflow Pipelines
In order to access Kubefow Pipelines, users can either deploy them independently or as part of the Kubeflow project. For simplified deployment, we recommend using Charmed Kubeflow.
- Deploy Charmed Kubeflow following the tutorial. You can do it on any environment, including public cloud or on-prem. Ensure that you have enough resources available, so you do not bump into problems along the way
- Access the Kubeflow dashboard. In case you are accessing it from a VM or from a public cloud, please ensure that you change the SOCKs proxy settings. There you will have different options, including to upload an existing pipeline or create a new one.
- Clone this repository from Github which contains a simple example of how to use some of the components of Kubeflow
- Access the examples from the Notebook. There are several pipelines created which you can run, edit or play with. Of course, they are just examples. In order to build your own pipeline, check the official documentation of the Kubeflow project.
Further reading
What is Kubeflow?
Kubeflow is the foundation of tools for AI Platforms on Kubernetes. AI platform teams can build on top of Kubeflow, deploy the entire reference platform, or use each project independently to meet their specific needs.
The Kubeflow reference platform is composable, modular, portable, and scalable, backed by an ecosystem of Kubernetes-native open source projects for each stage of the AI/ML Lifecycle.
Install Kubeflow
The Kubeflow project is dedicated to making machine learning workflows on Kubernetes simple, portable and scalable. With Charmed Kubeflow, you can forget about operational issues and platform compatibility. Thanks to the power and flexibility of Juju, our open source operator framework, you can deploy Charmed Kubeflow on top of any CNCF-compliant Kubernetes distribution.
Use Kubeflow on desktop, bare-metal, public cloud, or edge servers.
Newsletter signup
Related posts
Unlocking Edge AI: a collaborative reference architecture with NVIDIA
The world of edge AI is rapidly transforming how devices and data centers work together. Imagine healthcare tools powered by AI, or self-driving vehicles...
How to deploy Kubeflow on Azure
Kubeflow is a cloud-native, open source machine learning operations (MLOps) platform designed for developing and deploying ML models on Kubernetes. Kubeflow...
7 considerations when building your ML architecture
As the number of organizations moving their ML projects to production is growing, the need to build reliable, scalable architecture has become a more pressing...