
LLMs explained: how to build your own private ChatGPT

Andreea Munteanu
on 30 August 2023
Tags: AI Roadshow , AI/ML , AIML , CanonicalAIRoadshow , Kubeflow , MLOps
Large language models (LLMs) are the topic of the year. They are as complex as they are exciting, and everyone can agree they put artificial intelligence in the spotlight. Once LLms were released to the public, the hype around them grew and so did their potential use cases – LLM-based chatbots being one of them.
While large language models have been available for some time, there are still a lot of challenges when it comes to building your own project. This blog walks you through the process of building your private ChatGPT using open source tools and models.

Key considerations for building an LLM-based chatbot
Before getting started with your own LLM-based chatbot, there are a couple of aspects you should consider:
- Define the scope of the chatbot and the value that it is expected to provide.
- Understand the target audience of the chatbot, including details such as cultural habits, demographics or language preferences.
- Determine the data sources needed for the chatbot, as well as any constraints that they might come with. Check data accuracy, collection processes and data gathering frequency.
- Take the necessary integrations into account, so users can interact with the chatbot seamlessly. For example, using mobile apps, websites and APIs.
- Ensure that the chatbot follows ethical guidelines, promotes unbiased interactions and follows your industry’s compliance requirements.
- Consider the scalability options of the project.
LLMs explained: what happens behind the scenes?
LLM-based chatbots are a lot more advanced than standard chatbots. In order to achieve better performance, they need to be trained using a much larger dataset. They also need to be able to understand the context of the questions that users ask. How does this work in practice?
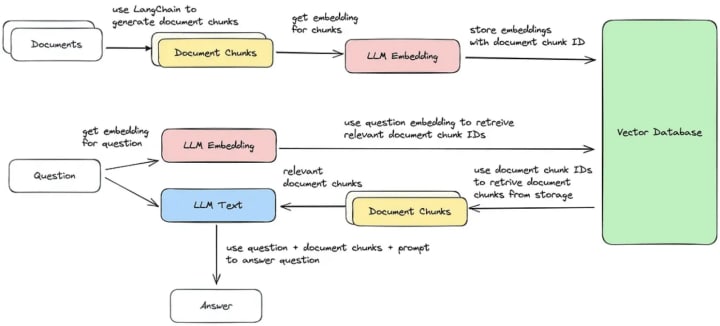
As shown in the image below, the user’s questions generate a prompt that searches a database where the data source is stored. Once the answer is identified, it is sent to the LLM and later to the user. There are additional technical steps performed, which ensure better performance, low latency and accurate answers.
This image illustrates Llama 2, an open source LLM. But other LLMs work in a similar fashion, varying slightly depending on the use case. The submitted query is turned into embeddings (numerical representations of words, phrases or sentences) that are stored in a vector database. At the same time, a search for similar enquiries is performed, such that relevant chunk documents can be retrieved. The open source LLM model is used to contextualise the data and generate an answer that is easy to understand by the user. As the image shows, LLMs can pull data from different types of documents, from text files to website data.

Now that we have a basic understanding of how LLMs work, let’s outline how you can start building one.
LLMs explained: how to get started?
Before building any project that uses a large language model, you should clearly define the purpose of the project. Make sure you map out the goals of the chatbot (or initiative overall), the target audience, and the type of skills used to create the project. This will ensure that the project meets your organisation’s needs and solves an actual problem. This step may seem intuitive – it’s quite common for any new machine learning initiative. The novelty comes next.
Gather the necessary data
Once a machine learning project has a clear scope defined, ensuring that the necessary data is available is crucial for its success. This part of the process can be split into two activities:
- Define the data sources needed for the project: depending on the type of questions that you expect your private ChatGPT to answer, it will need data from different sources. For example, if you expect it to answer frequently asked questions, you will need to provide them.
- Check for their availability and accuracy: it is not enough to know which data you need, you also need the data to be available and as accurate as possible. Depending on the target audience, having accurate data will define how trustworthy your project will be.
LLM Embeddings
As mentioned earlier, embeddings are numerical representations of words, phrases or sentences, capturing their context and meaning. They are used to represent the text in a manner that can be processed by machine learning algorithms.
Once data sources are chosen, they need to be transformed into embeddings, such that they can be used by different machine learning models. In order to get there, you need to generate document chunks in an intermediary step. After generating the embeddings of the document chunks, they are stored in a vector database, together with their chunk ID, such that they can be decoded later in the process.
Choose the right large language model (LLM)
Since there are many open source large language models, there are plenty of options to choose from. You don’t have to build everything from scratch.
The GPT series of LLMs from OpenAI has plenty of options. Similarly, HuggingFace is an extensive library of both machine learning models and datasets that could be used for initial experiments. However, in practice, in order to choose the most suitable model, you should pick a couple of them and perform some experiments. Assess their performance, by keeping their cost and latency as possible trade-offs.
In sum, when selecting a model, you need to consider a few things:
- Mandatory features of the model that are needed for your project
- Available resources
- Desired performance
- Cost considerations
Fine-tune the model
After choosing the model, the next step is to fine-tune it based on the custom knowledge you have. This will be possible using the embeddings you have generated. It will help the model learn and understand the specific context in which it will be used.
In order to perform this part of the project, you will need to create a pipeline dedicated to fine-tuning. Tools such as Charmed Kubeflow, integrated with Charmed MLFlow, are suitable open source options to move forward. The fine-tuned model can be then pushed to a repo such as HuggingFace and ideally further monitored using solutions such as Seldon Core or Grafana and Prometheus.
Make your private ChatGPT available
The success of any project is defined by the number of people who use it. This means you need to make the private ChatGPT available to the target audience. It might mean building a UI or creating an API that enables users to quickly ask their questions. Options such as Flask or Streamlit are two options that can help.
Summing up
To sum up, building a private ChatGPT is fun and can be a lot easier with available open source models and tools. Using open source enables enthusiasts and professionals to try things quickly at a low cost. The steps described above should help you get you started quickly, but depending on your use case, target audience, and available data, the timelines can increase.
Make sure to visit our roadshow to learn how to go from zero to hero with open source LLMs.
LLMs explained at the Canonical AI Roadshow

Canonical AI Roadshow will take our experts around the world to talk about large language models, open source machine learning operations (MLOps), generative AI and how to run AI at scale. What’s in store for you?
- Engaging demos: Discover hands-on insights into how to build, manage and scale your LLM projects.
- Expert insights: Learn from Canonical’s AI experts and get a glimpse into the possibilities open source tools offer to build your own ChatGPT.
- Networking: connect with us and discuss how these solutions can empower your unique goals.
Meet Maciej Mazur, AI/ML Principal Field Engineer, and Andreea Munteanu, MLOps Product Manager, to learn more about building LLMs with open source. Our roadshow will take us to:
- Europe:
- Amsterdam, Netherlands
- Bilbao, Spain
- Riga, Latvia
- Paris, France
- North America:
- Austin, Texas
- Chicago, Illinois
- Las Vegas, Nevada
- Middle East and Africa: Dubai, UAE
- Central and South America: São Paulo, Brazil
If you want to read more AI/ML content, follow us on Medium or listen to our podcast.
Enterprise AI, simplified
AI doesn’t have to be difficult. Accelerate innovation with an end-to-end stack that delivers all the open source tooling you need for the entire AI/ML lifecycle.
Newsletter signup
Related posts
Let’s meet at AI4 and talk about AI infrastructure with open source
Date: 11 – 13 August 2025 Booth: 353 Book a meeting You know the old saying: what happens in Vegas… transforms your AI journey with trusted open source. On...
Unlocking Edge AI: a collaborative reference architecture with NVIDIA
The world of edge AI is rapidly transforming how devices and data centers work together. Imagine healthcare tools powered by AI, or self-driving vehicles...
Canonical announces Ubuntu support for the NVIDIA Rubin platform
Official Ubuntu support for the NVIDIA Rubin platform, including the NVIDIA Vera Rubin NVL72 rack-scale systems, announced at CES 2026 CES 2026, Las Vegas. –...